CS4L9——顺序存储和链式存储
数据结构
数据结构是计算机存储、组织数据的方式(规则)
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合
比如自定义的一个 类 也可以成为一种数据结构 自己定义的数据组合规则、
不需要把数据结构想的太复杂,简单来说,就是人定义的 存储数据 和 表示数据之间的 规则而已
常用的数据结构(前人总结和制定的一些经典规则):数组、栈、队列、链表、树、图、堆、散列表
顺序存储和链式存储 是数据结构中两种 存储结构
线性表
线性表是一种数据结构,是由n个具有相同特性的数据元素的有限序列
比如数组、ArrayList、Stack、Queue、链表等等
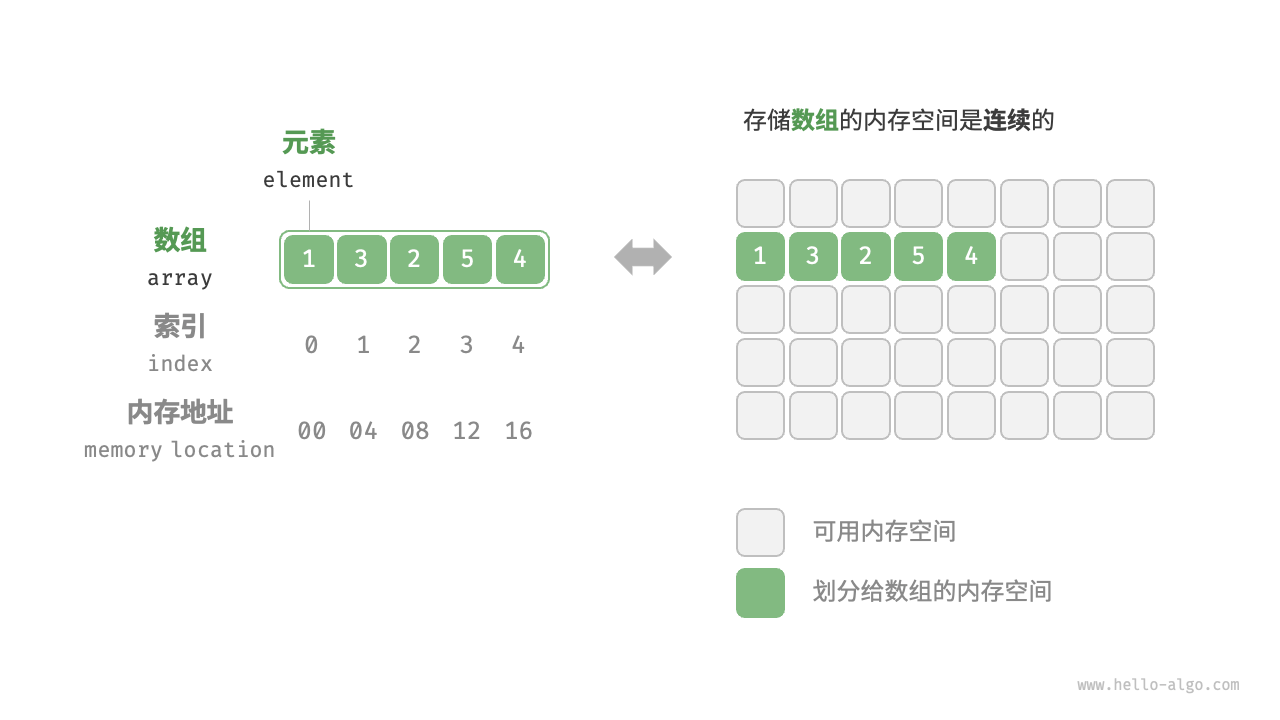
顺序存储
数组、Stack、Queue、List、ArrayList —— 顺序存储
只是 数组、Stack、Queue 的 组织规则不同而已
顺序存储就是用一种地址连续的存储单元依次存储线性表的各个数据元素
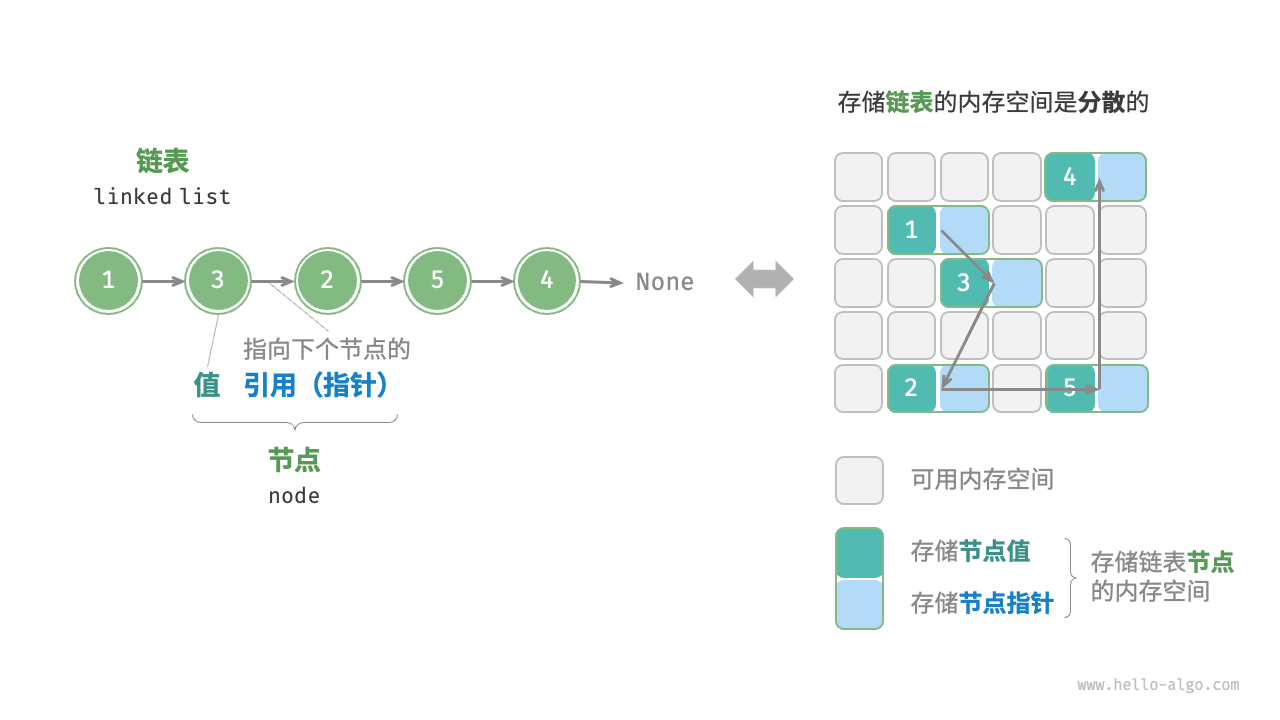
链式存储
单向链表、双向链表、循环链表 —— 链式存储
链式存储(链接存储):用一组任意的存储单元(节点)存储线性表中的各个数据元素
最基本的节点包括值和指向下一个节点的地址
实现一个最简单的单向链表
单向链表顾名思义,链表的一个节点只存储值和下一个节点的地址,
因此节点只能访问下一个节点,而不能访问上一个节点
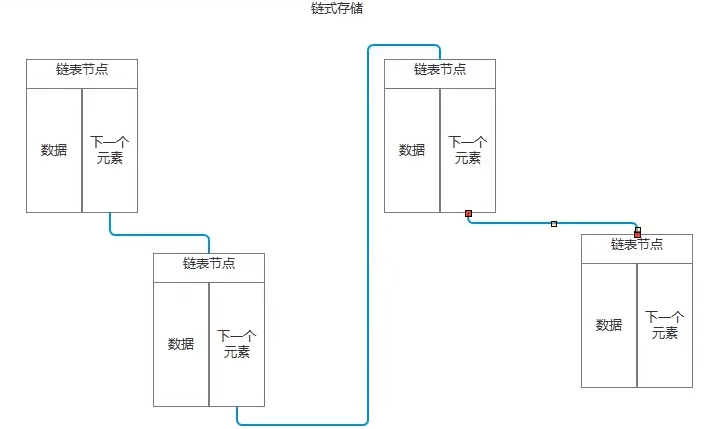
因此,节点类可以实现为:(使用泛型限制存储的类型)
1
2
3
4
5
6
7
8
9
10
11
| class LinkedNode<T>
{
public T value;
public LinkedNode<T> nextNode;
public LinkedNode(T value)
{
this.value = value;
}
}
|
使用构造函数来初始化节点存储的值,然后对 nextNode 赋值使节点得到下一个节点的消息
1
2
3
4
5
| LinkedNode<int> node1 = new LinkedNode<int>(1);
LinkedNode<int> node2 = new LinkedNode<int>(2);
node1.nextNode = node2;
node2.nextNode = new LinkedNode<int>(3);
node2.nextNode.nextNode = new LinkedNode<int>(4);
|
对于单向链表类本身(使用泛型限制存储的类型),我们需要存储第一个元素和最后一个元素
然后实现增和删的方法,每次增加节点时,需要让末尾的节点指向新增加的节点,
删除值时,需要遍历节点得到存储对应值的节点,若找到移除节点,设置移除节点的上一个节点指向其下一个节点,这样就是移除出了链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| class LinkedList<T>
{
public LinkedNode<T> head;
public LinkedNode<T> last;
public void Add(T value)
{
LinkedNode<T> node = new LinkedNode<T>(value);
if (head == null)
{
head = node;
last = node;
}
else
{
last.nextNode = node;
last = node;
}
}
public void Remove(T value)
{
if (head == null)
{
return;
}
if (head.value.Equals(value))
{
head = head.nextNode;
if (head == null)
{
last = null;
}
return;
}
LinkedNode<T> node = head;
while (node.nextNode != null)
{
if (node.nextNode.value.Equals(value))
{
if (node.nextNode.value.Equals(last.value))
{
last = node;
}
node.nextNode = node.nextNode.nextNode;
break;
}
else
{
node = node.nextNode;
}
}
}
}
|
这时,我们便得到了一个最简单的链表
如果要遍历链表,得到链表的首节点,读取值,然后获取其下一个节点,再读取值,再获取下一个节点,
循环执行以上步骤直到节点不指向任何节点,说明已经遍历到最后一个节点,这样就完成了遍历链表所有节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| LinkedList<int> link = new LinkedList<int>();
link.Add(1);
link.Add(2);
link.Add(3);
link.Add(4);
Console.WriteLine("第一次遍历");
LinkedNode<int> node = link.head;
while(node != null)
{
Console.WriteLine(node.value);
node = node.nextNode;
}
link.Remove(2);
Console.WriteLine("第二次遍历");
node = link.head;
while (node != null)
{
Console.WriteLine(node.value);
node = node.nextNode;
}
link.Remove(1);
Console.WriteLine("第三次遍历");
node = link.head;
while (node != null)
{
Console.WriteLine(node.value);
node = node.nextNode;
}
link.Add(99);
Console.WriteLine("第四次遍历");
node = link.head;
while (node != null)
{
Console.WriteLine(node.value);
node = node.nextNode;
}
link.Remove(99);
Console.WriteLine("第五次遍历");
node = link.head;
while (node != null)
{
Console.WriteLine(node.value);
node = node.nextNode;
}
link.Add(88);
Console.WriteLine("第六次遍历");
node = link.head;
while (node != null)
{
Console.WriteLine(node.value);
node = node.nextNode;
}
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| 第一次遍历
1
2
3
4
第二次遍历
1
3
4
第三次遍历
3
4
第四次遍历
3
4
99
第五次遍历
3
4
第六次遍历
3
4
88
|
顺序存储和链式存储的优缺点
从增删查改的角度去思考
- 增:链式存储 计算上 优于顺序存储(中间插入时链式不用像顺序一样去移动位置)
- 删:链式存储 计算上 优于顺序存储(中间删除是链式不用像顺序一样去移动位置)
- 查:顺序存储 使用上 优于链式存储(数组可以直接通过下标来得到元素,链式需要遍历)
- 改:顺序存储 使用上 优于链式存储(数组可以直接通过下标来得到元素,链式需要遍历)
扩展阅读,关于数据结构的使用:用链表的目的是什么?省空间还是省时间? - 知乎 (zhihu.com)
