
UPL9-9——降低 Shader 计算量
UPL9-9——降低 Shader 计算量
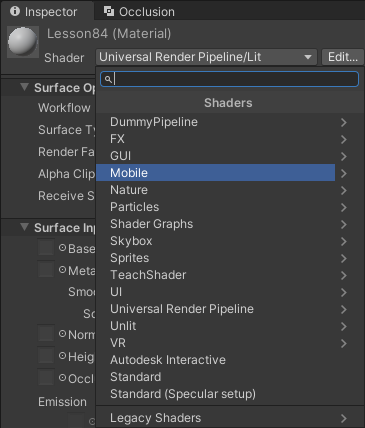
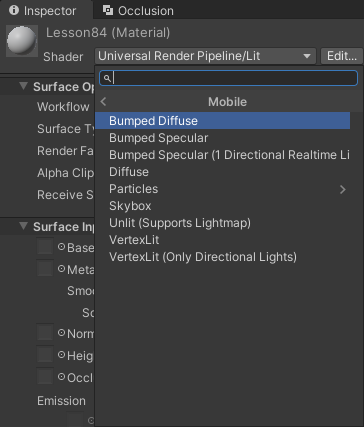
尽量使用针对移动平台的着色器
Unity 中内置了很多专门针对移动平台的 Shader,那么即使我们开发的是非移动平台项目也可以选择使用它
前提:使用这些 Shader 带来的效果损失项目是可以接受的
这样我们不需要修改任何 Shader 代码,直接改变使用的内置 Shader 就能带来明显性能提升
使用小的数据类型并且避免精度转换
-
在 GPU 里使用更小的数据类型来计算比使用更大的数据类型速度可能会更快(尤其是在移动端时)
因此我们可以更多的选择使用
half、fixed,尽量少用float类型注意:桌面 GPU 中,
half 常常会被当作float处理,性能提升有限 -
我们应该避免频繁的在低精度和高精度之间相互转换,尽量在同一 Shader 内保持一致的精度选择,因为精度转换会损耗性能
尽量使用GPU优化的辅助函数
Unity 中提供了很多内置 Shader 库文件,比如:
-
UnityCG.cginc -
UnityShaderVariables.cginc -
Lighting.cginc -
HLSLSupport.cginc
等等(具体可见:US2S3L13——CG内置文件)
这些文件中包含了很多封装好的函数和宏,这些内容一方面封装了 HLSL / CG 的常用计算
另一方面还对跨平台兼容性(坐标系、色彩空间等)做了优化
当我们有相关计算需求时,我们可以引用这些文件,并使用这些内置函数来进行计算
比如:
- 常规运算:
abs()、sign()、min()、max()、saturate()、clamp() - 插值与混合:
lerp(a,b,t)、smoothstep(edge0,edge1,x) - 三角函数:
sin()、cos()、tan()、asin()、acos()、atan2() - 指数与对数:
exp()、exp2()、log()、log2()、pow(x,y)、sqrt()、rsqrt()(快速倒数平方根) - 向量操作:
dot()(点积)、cross()(叉积)、normalize()、length()、distance()、reflect()(反射向量)、refract()(折射向量)、faceforward() - 亮度/灰度:
Luminance() - Gamma / Linear 转换:
GammaToLinearSpace(col)、LinearToGammaSpace(col) - 顶点空间变换:
UnityObjectToClipPos(v)、UnityObjectToWorldPos(v)、UnityWorldToObjectDir(d)、UnityWorldToClipPos(v) - 法线变换:
UnityObjectToWorldNormal(n)、UnityWorldToObjectNormal(n) - 采样/纹理工具:
tex2D(sampler, uv)、texCUBE(sampler, dir)
等等(具体可见:US2S3L12——CG内置函数)
在实际开发中,优先使用 Unity 提供的这些函数,可以避免重复造轮子,并确保在不同平台上获得正确且高效的结果
参考文档:
-
HLSL / CG内置函数(Unity 基本支持)
https://learn.microsoft.com/en-us/windows/win32/direct3dhlsl/dx-graphics-hlsl-intrinsic-functions
-
Unity 封装的内容
https://docs.unity3d.com/Manual/SL-UnityShaderVariables.html
-
Unity内置着色器源码,可以看到内置文件(需要使用国外 IP)
https://unity.com/releases/editor/whats-new/6000.0.58f1#installs
删除不必要的输入数据
在 Shader 开发中
- 顶点着色器阶段:需要自定义结构体决定需要传入和使用哪些模型数据
- 片元着色器阶段:需要自定义结构体决定从顶点着色器中传出哪些数据
我们应该尽量避免传入和传出不需要使用的数据
比如:
- 在顶点着色器中如果不需要用到法线、切线等数据,就不要在结构体中进行声明
- 在片元着色器中不需要用到的数据也不要从顶点传出,否则会进行插值相关的计算
只公开所需的变量
在 Shader 中的应该只保留真正需要外部控制的变量成为材质参数
这样可以减少常量缓冲区传输的开销,还可以让 Inspector 窗口更简洁
如果某些成员是固定值,可以直接写死在 Shader 中,不用公开成材质参数
预计算
对于一些常用不变的数据,我们可以提前计算好,放在 CPU 或者纹理贴图中,不要每帧都在 Shader 中重复计算
举例:
-
光照烘焙贴图就是把光照结果预先算好放入了光照纹理中,直接取出来使用
-
一些复杂函数结果,可以预烘焙为 LUT 纹理,Shader 内直接从其中采样即可
LUT 纹理:Look-Up Table(查找表纹理)
把复杂、昂贵的计算结果 提前存到一张纹理里,在 Shader 中直接通过坐标去“查表”取结果,用一次纹理采样(内存带宽消耗)替代复杂的数学计算
比如:
假设你要频繁算pow(x,2.2) 来做 Gamma 校正,如果不用 LUT 纹理,每次计算开销大:float gammaCorrect = pow(x, 2.2);
我们可以先在 CPU 或工具里预生成一个 256 像素宽的 1D 纹理,存放[0,1] 区间的pow(x,2.2) 值
在 Shader 中我们直接在该纹理中采样即可:float gammaCorrect = tex2D(_GammaLUT, float2(x, 0)).r;
减少逐像素计算
能在顶点阶段计算的,就不要放在片元阶段,因为 顶点数量 绝大多数情况下都是远远小于 像素数量 的
顶点 到 片元阶段 中插值计算的效率 是优于 在片元中逐像素计算的
比如:如果只是顶点颜色渐变,直接在顶点算好,再插值到片元
注意:并不是所有效果都适合从片元转移到顶点计算
合并多次计算
在 Shader 编程时,避免重复算同样的表达式,应该把结果存起来复用
-
错误做法:
1
2float a = sin(x) * 0.5;
float b = sin(x) * 2.0; -
正确做法:
1
2
3float s = sin(x);
float a = s * 0.5;
float b = s * 2.0;
利用常量缓冲区
应该把多个 Shader 共享的常量数据(灯光参数、矩阵、全局材质参数),放到常量缓冲区(CBUFFER)中
这样的好处是 一次传输,多处使用,减少 CPU 到 GPU 的频繁数据更新
常量缓冲区(Constant Buffer,简称 CBuffer)是 GPU 内存中一块 专门存放统一变量(Uniforms)的区域,使用方式:
Shader 代码中:
1 | CBUFFER_START(自定义名字 或 Unity内置常量缓冲区名) |
内置常量缓冲区名
-
UnityPerCamera:相机相关(矩阵、位置) -
UnityPerFrame:时间、屏幕尺寸、帧率相关 -
UnityPerDraw:物体的世界矩阵等 -
UnityPerMaterial:材质参数
C# 代码中:
1 | int BaseColorID = Shader.PropertyToID("_BaseColor"); |