
UPL10-5——材质与Shader资源优化
UPL10-5——材质与Shader资源优化
前置知识:US2S2L1——材质与Shader
材质与 Shader 内存优化的核心理念
-
材质优化目标:
最小化 纹理内存占用
降低 材质实例数量
降低 Shader 的计算负荷 -
Shader 优化目标:
减少变体数量,简化计算逻辑
-
核心矛盾:视觉质量 与 内存占用 和 GPU 计算负荷 的平衡
-
主要优化原则:关键角色高质量,大量物体低成本
材质优化流程:
- 设置合适的纹理压缩格式和尺寸
- 合理配置 Mip Maps 和 Read/Write
- 使用通道合并和纹理图集
- 开启纹理流送管理内存
Shader 优化流程:
- 剥离不需要的 Shader 变体
- 建立 Shader LOD 分级系统
- 简化 Shader 代码和计算
- 适配目标渲染管线
材质管理流程:
- 使用材质共享而非复制
- 按需使用
MaterialPropertyBlock - 实现材质资源生命周期管理
- 建立材质复杂度分级标准
监控维护流程:
- 定期使用 Profiler 分析内存
- 建立性能预算和预警机制
- 代码审查避免常见内存问题
纹理资源导入优化
详见:UPL10-3——纹理资源优化
纹理压缩格式
平台 首选 备选 HDR格式 法线 遮罩贴图 特殊用途 PC BC7 BC3 BC6H BC5 DXT1|BC1 BC1、BC4(单通道) Android ASTC 4x4 ETC2 4bit ASTC HDR 6x6 ASTC 5x5 ETC2 4bit ASTC 6x6(远景、小道具) IOS ASTC 4x4 ASTC 6x6 ASTC HDR 4x4 ASTC 5x5 ASTC 6x6|8x8 EAC R/RG WebGL ASTC 4x4 DXT1/DXT5,ETC2,PVRTC BC6H BC5 DXT1|BC1 ASTC 6x6 / DXT1 作用:大幅减少纹理在磁盘和内存中的占用空间,不同格式在质量、大小、兼容性之间权衡
建议:
- 移动端:ASTC > ETC2 > PVRTC
- PC 端:BC/DXT 系列
- WebGL:不要默认 ASTC 可用,要根据平台和浏览器而定
Max Size(最大尺寸)
控制纹理导入时的最大尺寸
作用:防止过大的纹理占用不必要的内存,根据使用距离和重要性设置合适尺寸
建议:
- 主角 / 重要道具:1024*1024 或 2048*2048
- 场景物件:512*512 或 1024*1024
- UI 元素:按实际显示尺寸,避免缩放
- 远景贴图:256*256 或 512*512
Mip Maps(多级渐远纹理)
- 勾选:生成纹理金字塔,远处使用低分辨率版本
- 不勾选:始终使用全分辨率纹理
作用:减少远处物体的纹理采样开销和闪烁问题,增加约 33% 的内存占用,但提升渲染性能
建议:
- 3D 场景物体:开启 Mip Maps
- UI 元素、Sprite、全屏特效:关闭 Mip Maps
Read/Write
- 勾选:CPU 和 GPU 都可访问纹理数据
- 不勾选:仅 GPU 可访问,上传后释放 CPU 内存
建议:运行时不需要修改的纹理务必取消勾选,需要动态修改的纹理(如程序生成)才开启
纹理导入决策流程:
- 重要角色贴图 → 合适尺寸 + ASTC/BC压缩 + Mip Maps 开启
- UI贴图 → 精确尺寸 + 适当压缩 + Mip Maps 关闭
- 场景贴图 → 中等尺寸 + 较高压缩 + Mip Maps 开启
- 永远不需要修改的纹理 → 不要勾选 Read/Write
纹理数据精简策略
从源纹理数据和布局上优化
通道分离与合并
将多个单通道纹理合并到 RGBA 通道中
示例:
- 原:金属度、粗糙度、环境光遮蔽、高度各一张 1024 灰度图 = 16MB
- 合并:一张 1024 RGBA 图,各占一个通道 = 4MB
作用:大幅减少纹理数量和内存占用,同时减少 3 次纹理采样
纹理图集
将多个小纹理打包到一张大纹理中
作用:减少 DrawCall,提高合批效率,减少纹理切换开销。优化内存碎片
注意:不要过度打包导致空白区域浪费
纹理流 (Texture Streaming)
动态加载不同Mip级别的纹理
作用:按需加载纹理数据,减少内存峰值,根据距离和重要性动态调整纹理质量
建议:开放大世界游戏强烈推荐开启,注意设置合理的预算和优先级
Crunch(紧缩)压缩
只会压 磁盘/包体,不降显存,加载时需要 CPU 解压,移动端慎用
Shader 内存与性能优化
Shader 变体和复杂度是优化重点
-
Shader 变体控制
使用预处理指令控制变体生成,示例:
-
强制生成所有指定的变体组合
#pragma multi_compile1
#pragma multi_compile _ _SHADOWS_SOFT
这会生成 2 个 Shader变体
一个不包含_SHADOWS_SOFT 关键字(_ 代表空或默认)
一个包含_SHADOWS_SOFT关键字 -
智能生成变体
#pragma shader_feature只有那些在实际使用的材质中启用了相应关键字的变体才会被生成
1
#pragma shader_feature _EMISSION
-
显式跳过某些变体的生成
#pragma skip_variants1
#pragma skip_variants POINT_COOKIE
如果你确定你的游戏永远不会使用
POINT_COOKIE 类型的光源
就可以用skip_variants跳过它,不生成这个变体
作用:减少编译后的 Shader 变体数量,降低内存占用和构建时间
建议:只保留实际使用的特性组合
-
-
配置变体剥离
在 Edit -> Project Settings -> Graphics -> Shader Stripping (着色器剥离) 中配置变体剥离

-
Lightmap Modes (光照贴图模式)

-
Automatic:Unity 会自动分析项目设置和场景内容、只保留实际使用的光照贴图编码格式变体
-
Custom (自定义):手动选择需要保留的光照贴图模式
选择 Custom 后会出现如下设置项:
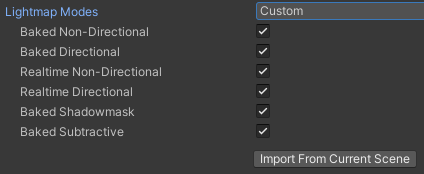
-
Baked Non-Directional (烘焙非定向光照贴图):预计算的光照贴图,不包含方向信息
-
Baked Directional (烘焙定向光照贴图):预计算的光照贴图,包含方向信息
-
Realtime Non-Directional (实时非定向光照贴图):实时全局光照的非定向模式
-
Realtime Directional (实时定向光照贴图):实时全局光照的定向模式
-
Baked Shadowmask (烘焙阴影遮罩):混合光照模式,结合烘焙和实时阴影
-
Baked Subtractive (烘焙减法模式):简化的混合光照模式
-
Import From Current Scene (从当前场景导入):自动分析当前打开的场景,只保留场景中实际使用的光照贴图模式
-
勾选某个模式:
告诉 Unity:我的项目可能会使用这种光照模式
Unity 会在构建时保留所有与该模式相关的 Shader 变体
增加构建大小,增加内存占用,但确保该模式可用 -
取消勾选某个模式:
告诉 Unity:我的项目绝对不会使用这种光照模式
Unity 会在构建时彻底移除所有与该模式相关的 Shader 变体
减少构建大小,减少内存占用,但该模式将完全不可用
-
建议:移动端 - 取消勾选所有 Realtime 模式
-
-
Fog Modes (雾效模式)

-
Automatic:自动检测项目是否使用雾效,如果场景中没有启用雾效,会移除所有雾效变体
如果使用了雾效,只保留实际使用的雾效类型变体
-
Custom (自定义):手动选择需要保留的雾效模式
选择 Custom 后会出现如下设置项:
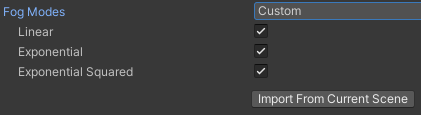
- Linear (线性雾)
- Exponential (指数雾)
- Exponential Squared (二次指数雾)
- Import From Current Scene (从当前场景导入):自动分析当前打开的场景,只保留场景中实际使用的雾效模式
关于 Unity 雾效,详细可见:US3S11L5——Unity自带全局雾效
-
-
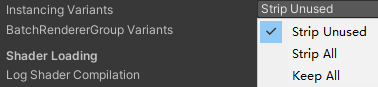
Instancing Variants (GPU 实例化变体)
-
Strip Unused (剥离未使用的)
移除没有被任何材质使用的 GPU 实例化变体,Unity 分析项目中所有材质球
如果 Shader 声明了#pragma multi_compile_instancing但没有材质启用 GPU Instancing
这些变体会被移除,只有实际启用了 GPU Instancing 的材质对应的变体会保留 -
Strip All (剥离所有)
强制移除所有 GPU 实例化相关的 Shader 变体
-
Keep All (保留所有)
强制保留所有 GPU 实例化变体,无论是否被使用
-
-
BatchRendererGroup Variants (批渲染组变体)

-
Strip if Entities Graphics Package is not installed (未安装 Entities Graphics 包时剥离)
智能检测并自动处理 DOTS 相关变体
-
Strip All (剥离所有)
强制移除所有 BatchRendererGroup 变体
-
Keep All (保留所有)
强制保留所有 BatchRendererGroup 变体
-
-
-
Shader LOD (Level of Detail)
为不同硬件配置提供多个细节级别,配置示例:
1
2
3SubShader { LOD 400 /*...*/ } // 高配:复杂效果
SubShader { LOD 200 /*...*/ } // 中配:简化效果
SubShader { LOD 100 /*...*/ } // 低配:基础效果作用:根据设备性能自动选择合适的 Shader 版本,保证低端设备的流畅运行
建议:为重要材质提供 3 个LOD级别,通过
Shader.maximumLOD全局控制 -
Shader 代码简化
-
优化策略:
- 减少纹理采样次数(合并采样)
- 简化数学计算(用近似代替精确)
- 使用更廉价的光照模型
- 移除不需要的顶点属性
-
作用:降低GPU计算负荷,提高渲染性能
-
建议:性能敏感平台使用简化版 Shader,为不同重要度的物体提供不同复杂度的 Shader
-
材质实例管理优化
避免材质复制和内存泄漏
-
材质共享策略
使用
renderer.sharedMaterial 而非renderer.material正确做法:
1
Material sharedMat = renderer.sharedMaterial; // 共享实例
错误做法:
1
Material newMat = renderer.material; // 创建副本!
作用:避免无意中创建材质副本导致内存泄漏,减少材质数量,便于合批
建议:所有相同外观的物体共享同一个材质实例 -
材质属性块 (
MaterialPropertyBlock)对需要个性化参数的物体使用
PropertyBlock,用于在运行时修改材质属性而不创建新的材质实例,示例:1
2
3MaterialPropertyBlock props = new MaterialPropertyBlock();
props.SetColor("_Color", customColor);
renderer.SetPropertyBlock(props);作用:在不创建材质实例的情况下修改渲染参数,保持合批能力的同时实现个性化
建议:大量相同网格但需要不同颜色/参数时使用 -
材质按需加载
使用资源管理系统控制材质生命周期
-
方法:
-
Addressables资源管理系统 -
AssetBundle动态加载
及时卸载不用的内容
-
-
作用:避免材质常驻内存,按场景和需求动态管理
-
建议:大项目必须实现材质资源管理策略
-
渲染管线与复杂度分级
根据渲染管线特性优化
-
Shader 复杂度分级体系
分级策略:
- 主角:完整 PBR + 法线 + 高光 + 实时阴影
- 主要NPC:简化 PBR + 法线 + 烘焙阴影
- 场景物件:简单漫反射 + 光照贴图
- 远景物体:Unlit Shader + 顶点色
作用:合理分配渲染预算,保证关键视觉质量的同时优化性能
建议:建立明确的材质复杂度标准 -
实时 VS 烘焙权衡
- 实时效果:动态物体、主要角色、交互元素
- 烘焙效果:静态场景、光照贴图、反射探针
作用:将计算开销从运行时转移到编辑时,大幅提升运行性能
建议:尽可能使用烘焙光照处理静态场景 -
合批优化
条件:
- 相同材质实例
- 相同 Shader 参数
- 合适的渲染顺序
作用:减少 DrawCall,提升 CPU 渲染效率
建议:通过材质共享和属性块优化合批条件,配合各种批处理方案使用
内存分析与监控
建立监控体系,及时发现问题
-
性能分析工具
- Profiler 中的 Memory:详细内存分析
- Frame Debugger:渲染状态分析
- Memory Profiler:深度内存诊断
作用:定位内存泄漏和性能瓶颈,监控资源加载和卸载
-
关键性能指标
- 纹理内存:监控纹理内存对整体内存占用情况的影响
- 材质数量:控制活跃材质实例数量
- Shader 变体:监控变体数量和编译时间
- DrawCall:监控 DrawCall 对性能的影响
-
内存优化检查点
- 纹理压缩格式是否正确
- Read/Write 是否误开启
- 材质实例是否意外复制
- Shader 变体是否过度生成
- 资源是否及时卸载